
Votre directeur commercial vient de taper le nom de votre entreprise dans ChatGPT. Résultat : rien, ou pire, votre concurrent direct cité à votre place. Vous n'êtes pas seul. Selon une analyse croisée sur 6 moteurs IA (ChatGPT, Claude, Mistral, Perplexity, Meta AI et Gemini), plus de 3 PME françaises sur 4 sont totalement absentes des réponses générées sur leur secteur d'activité.
Ce n'est pas une question de budget ni de notoriété. C'est une question d'erreurs précises et corrigeables. Certaines prennent 5 minutes à réparer. D'autres nécessitent un chantier de fond. Toutes ont un impact mesurable sur votre visibilité dans l'IA — ce qu'on appelle le GEO (Generative Engine Optimization).
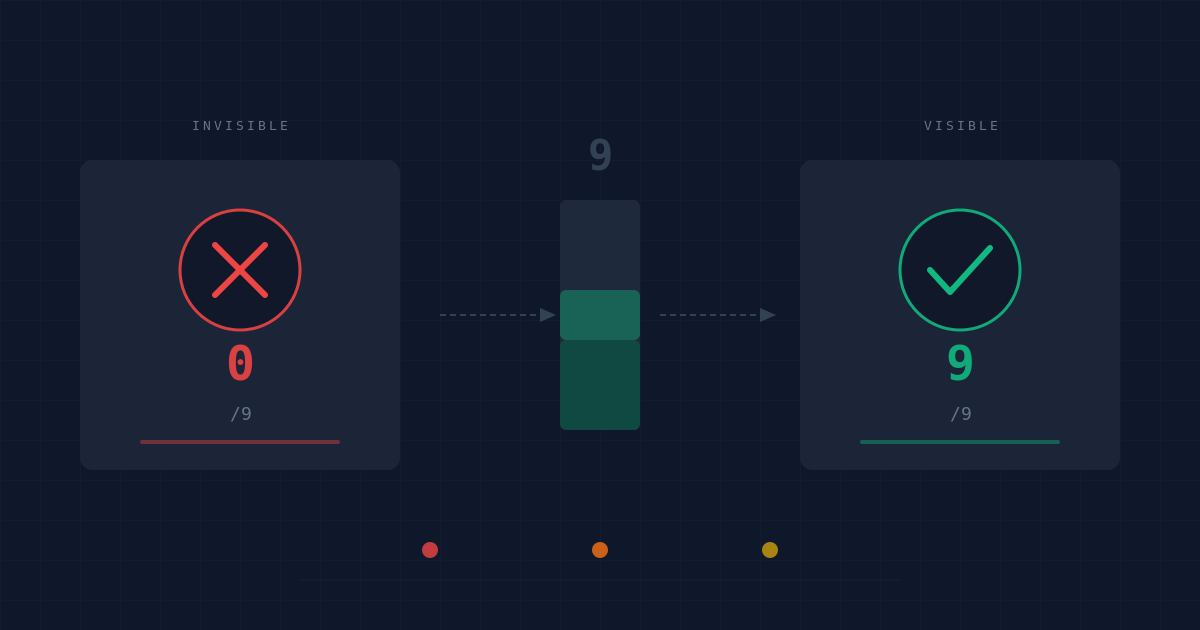
Ce guide classe les 9 erreurs les plus fréquentes en trois niveaux de gravité. À chaque erreur, une note de 0 ou 1 pour calculer votre score d'invisibilité en 20 minutes.
Pourquoi les PME sont plus touchées que les grandes marques
Les LLMs construisent leur connaissance d'une marque à partir de la fréquence et de la cohérence de ses mentions dans leurs données d'entraînement. Air France ou LVMH apparaissent dans des milliers d'articles, de communiqués de presse, de discussions Reddit, de contenus Wikipédia. Leur présence dans les IA est quasi automatique.
Une PME de 50 salariés, en revanche, n'existe peut-être que dans son propre site web et quelques annuaires. Si ces sources sont mal structurées, bloquées pour les robots ou dépourvues de données sémantiques, les modèles de langage n'ont tout simplement aucune matière pour générer une réponse vous concernant. Le vide sémantique est interprété comme une absence d'existence — pas comme une absence d'information.
La bonne nouvelle : chaque erreur ci-dessous est corrigeable. Et contrairement au SEO, les effets sur la visibilité GEO peuvent se manifester dans les semaines suivant la correction, pas les mois.
🔴 Erreurs critiques — visibilité nulle garantie
Ces trois erreurs ont un effet binaire : elles empêchent totalement les IA d'accéder à vos contenus ou de vous associer à votre secteur. Si vous en avez une seule, l'optimisation GEO n'a aucun sens avant correction.
Erreur 1 — Robots IA bloqués dans votre robots.txt
Depuis 2023, les principaux LLMs utilisent leurs propres user-agents pour crawler le web : GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot, Google-Extended, Meta-ExternalAgent. Si votre robots.txt contient Disallow: / pour ces bots, ou un User-agent: * trop restrictif, vous êtes littéralement invisible pour ces systèmes.
Vérification rapide : accédez à votresite.fr/robots.txt et cherchez les lignes mentionnant GPTBot, ClaudeBot ou un Disallow: / global. Un cabinet d'avocats parisien a ainsi découvert en 2025 que son prestataire web avait bloqué tous les robots « non-Google » pour « protéger le contenu » — résultat : zéro citation sur 6 IA testées sur la requête « avocat droit des affaires Paris ».
Correctif : autorisez explicitement GPTBot, ClaudeBot, PerplexityBot et Google-Extended. Temps de correction : 10 minutes via votre CMS ou Yoast.
Erreur 2 — Zéro mention sur des sources tierces
Les IA ne citent pas un site parce qu'il est bien fait. Elles citent une marque parce qu'elles l'ont rencontrée dans de nombreuses sources indépendantes. Un blog bien rédigé sur votre propre domaine ne suffit pas. Ce qui compte pour ChatGPT, Claude, Mistral, Perplexity, Meta AI et Gemini, c'est la densité de co-citations : votre nom apparaît-il dans des articles de presse, des comparatifs, des discussions Reddit, des contenus Wikipédia, des newsletters sectorielles ?
Une étude de Princeton (GEO Paper, 2024) a quantifié cet effet : les marques citées dans 50+ sources tierces ont une probabilité 4,3 fois supérieure d'apparaître dans les réponses des LLMs par rapport aux marques présentes uniquement sur leur propre site.
Vérification rapide : tapez le nom de votre entreprise entre guillemets dans Google. Si vous trouvez moins de 10 résultats hors de votre propre domaine, vous avez un problème d'autorité tierce.
Correctif : relations presse, guest posts, réponses expertes sur Quora et LinkedIn, inscription sur Capterra/G2 si vous êtes SaaS, annuaires sectoriels. Priorité : créer des "points d'ancrage" sur des domaines à forte autorité.
Erreur 3 — Contenu sans entités nommées ni contexte sectoriel
Les LLMs fonctionnent par associations d'entités. Pour être cité quand quelqu'un demande « quelle solution de gestion RH pour PME ? », votre marque doit avoir été associée, dans les sources crawlées, aux entités RH, gestion, PME, paie, SIRH, Workday, Sage, congés — et pas seulement sur une page générique « qui sommes-nous ».
La règle recommandée : 15+ entités nommées par tranche de 1 000 mots, avec une couverture sémantique complète de votre secteur. Un contenu purement promotionnel (« Notre solution est la meilleure du marché ») n'apporte aucune entité utile aux modèles. Un contenu qui explique, compare, contextualise — oui.
Vérification rapide : prenez vos 3 principales pages de contenu. Comptez les noms propres, termes techniques, concurrents mentionnés, certifications citées, cas d'usage décrits. Si vous arrivez à moins de 10 entités distinctes pour 1 000 mots, c'est insuffisant.
🟠 Erreurs graves — visibilité très dégradée
Ces trois erreurs ne bloquent pas complètement l'accès, mais elles réduisent drastiquement les chances d'être sélectionné dans une réponse. Les IA vous voient mais ne vous choisissent pas.
Erreur 4 — Pas de fichier llms.txt
Le llms.txt est un fichier texte placé à la racine de votre site (votresite.fr/llms.txt) qui indique aux IA ce que vous faites, qui vous êtes, quelles pages sont prioritaires à lire, et dans quel contexte vous positionner. Standard introduit par Jeremy Howard en 2024, il est désormais reconnu par les principaux crawlers IA.
Sans ce fichier, les LLMs doivent « deviner » votre positionnement à partir de votre site. Avec un llms.txt bien rédigé, vous leur fournissez directement le contexte : secteur d'activité, proposition de valeur en 3 phrases, pages clés à prioriser, terminologie exacte à employer pour vous décrire.
Vérification rapide : accédez à votresite.fr/llms.txt. Si la page renvoie une erreur 404, le fichier n'existe pas.
Erreur 5 — Pas de données structurées JSON-LD ou mauvais type
Les données structurées Schema.org en JSON-LD sont le langage machine que les IA lisent pour comprendre rapidement ce qu'est une page sans l'analyser mot à mot. Un `Organization` schema sur votre homepage indique votre nom officiel, secteur, adresse, logo, fondation. Un `SoftwareApplication` schema sur votre page produit détaille les fonctionnalités, prix, plateformes supportées.
Sans JSON-LD, les LLMs doivent inférer ces informations depuis le texte — avec un risque d'erreur et de confusion élevé. Une PME de Lyon dans la logistique peut facilement être confondue avec une PME homonyme de Paris dans le conseil si aucune donnée structurée ne précise le contexte.
Vérification rapide : utilisez le Google Rich Results Test sur votre homepage. Si aucun schéma n'est détecté, c'est l'erreur 5.
Erreur 6 — Contenu trop court ou 100 % commercial
Les LLMs préfèrent citer des sources qui expliquent plutôt que des sources qui vendent. Une page de 300 mots qui liste vos services avec des formules comme « expertise reconnue » et « accompagnement sur-mesure » n'apporte aucune valeur informative aux modèles. Elle ne sera pas sélectionnée comme source d'une réponse.
Une étude de Surfer SEO (2025) sur 10 000 pages analysées par les LLMs montre que les pages de 1 500 mots minimum avec une structure H2/H3 claire, des données chiffrées et des exemples concrets ont 2,8 fois plus de chances d'être citées. La profondeur informationnelle est un signal de fiabilité.
Vérification rapide : comptez les mots de vos 5 principales pages. Si aucune ne dépasse 800 mots, et si elles contiennent principalement des listes de services sans explication, vous avez l'erreur 6.
🟡 Erreurs modérées — visibilité partielle ou instable
Ces trois erreurs n'empêchent pas toute visibilité, mais créent des angles morts : vous apparaissez sur certaines IA ou certaines requêtes, mais pas de façon cohérente sur ChatGPT, Claude, Mistral, Perplexity, Meta AI et Gemini simultanément.
Erreur 7 — Nom de marque ambigu ou générique
Si votre entreprise s'appelle « Solutions Pro » ou « Digital Services », les LLMs ont du mal à vous distinguer de dizaines d'autres entités homonymes ou quasi-homonymes. Le modèle, face à l'ambiguïté, cite la marque la plus documentée parmi toutes celles portant un nom similaire — rarement vous.
Correctif : associez systématiquement votre nom de marque à des qualificatifs distinctifs dans tous vos contenus — ville, secteur précis, fondateur, technologie propriétaire. « Diria, la plateforme GEO française » est plus mémorisable pour un LLM que « Diria » seul.
Erreur 8 — Site uniquement en français avec terminologie générique
La quasi-totalité des données d'entraînement des LLMs est en anglais. Les termes techniques anglophones (SaaS, CRM, B2B, HR Tech, PropTech, FinTech, AI-native) sont sur-représentés dans les associations sémantiques des modèles. Si vos contenus n'utilisent jamais ces termes, les LLMs peuvent ne pas savoir dans quelle « case » vous ranger.
Ce n'est pas une invitation à écrire en anglais — votre audience est française. C'est une invitation à intégrer naturellement la terminologie de votre industrie, souvent anglophone, dans vos contenus français : « notre outil GEO (Generative Engine Optimization) », « notre approche RAG (Retrieval-Augmented Generation) », etc.
Erreur 9 — Pas de FAQ structurée
Les FAQ sont l'une des structures de contenu les plus favorables à la citation par les LLMs. Pourquoi ? Parce qu'elles reproduisent exactement le format question/réponse que les IA génèrent. Une FAQ avec le schema FAQPage en JSON-LD fournit aux modèles des paires Q/R pré-formatées, directement réutilisables dans leurs réponses.
Perplexity, qui cite ses sources de manière transparente, a un tropisme particulier pour les pages FAQ bien structurées : elles représentent 34 % des sources citées dans ses réponses selon une analyse de 500 requêtes sectorielles (Diria, mai 2026).
Correctif : créez une page FAQ de 10 à 20 questions sur votre secteur (pas seulement vos produits), avec schema FAQPage en JSON-LD. Réponses entre 100 et 200 mots chacune, précises et actionnables.
Calculez votre score d'invisibilité en 20 minutes
Répondez à chaque question par 0 (erreur présente) ou 1 (erreur absente) :
| # | Question de diagnostic | Gravité | Score |
|---|---|---|---|
| 1 | GPTBot, ClaudeBot, PerplexityBot sont-ils autorisés dans votre robots.txt ? | 🔴 Critique | 0 ou 1 |
| 2 | Votre marque est-elle mentionnée dans 10+ sources tierces (hors votre domaine) ? | 🔴 Critique | 0 ou 1 |
| 3 | Vos pages principales contiennent-elles 15+ entités nommées pour 1 000 mots ? | 🔴 Critique | 0 ou 1 |
| 4 | Un fichier llms.txt existe-t-il à la racine de votre site ? | 🟠 Grave | 0 ou 1 |
| 5 | Des données structurées JSON-LD (Organization ou SoftwareApplication) sont-elles présentes ? | 🟠 Grave | 0 ou 1 |
| 6 | Vos principales pages dépassent-elles 1 500 mots avec données chiffrées et exemples ? | 🟠 Grave | 0 ou 1 |
| 7 | Votre nom de marque est-il associé à des qualificatifs distinctifs dans tous vos contenus ? | 🟡 Modérée | 0 ou 1 |
| 8 | Utilisez-vous la terminologie technique anglophone de votre secteur dans vos contenus ? | 🟡 Modérée | 0 ou 1 |
| 9 | Une page FAQ avec schema FAQPage existe-t-elle sur votre site ? | 🟡 Modérée | 0 ou 1 |
Interprétez votre score
0 à 3 / 9 : Invisibilité totale probable. Les IA n'ont pas la matière pour vous citer. Commencez immédiatement par les erreurs critiques (1, 2, 3).
4 à 6 / 9 : Visibilité partielle. Vous existez pour les IA dans certains contextes, mais vous perdez la majorité des requêtes pertinentes. Corrigez les erreurs graves en priorité.
7 à 9 / 9 : Base GEO solide. Concentrez-vous désormais sur l'autorité tierce (Run 16) et la profondeur sémantique pour passer de la citation occasionnelle à la citation systématique.
Par où commencer selon votre profil
Toutes les PME ne partent pas du même point. Voici trois profils typiques et leur feuille de route prioritaire.
PME sans présence IA : débutez par le robots.txt (Erreur 1 — 10 minutes), puis créez un contenu pilier de 2 000 mots sur votre métier principal (Erreur 3 et 6), puis installez JSON-LD Organization sur votre homepage (Erreur 5). Ces trois actions seules peuvent vous faire passer de 0 à 30/100 en visibilité IA en 4 semaines.
PME avec site étoffé mais sans autorité tierce : votre problème est la Erreur 2. Priorisez 5 à 10 mentions sur des sites tiers de qualité (presse sectorielle, Capterra, annuaires professionnels). C'est le levier à plus fort impact pour dépasser 50/100 de visibilité.
PME avec contenus et autorité: travaillez la cohérence sémantique sur ChatGPT, Claude, Mistral, Perplexity, Meta AI et Gemini. Vérifiez que vous êtes bien cité sur chacun, avec le bon positionnement, le bon secteur, les bons cas d'usage associés. C'est le travail de monitoring GEO.
Questions fréquentes sur les erreurs GEO des PME
Combien de temps faut-il pour corriger ces erreurs ?
Les erreurs techniques (robots.txt, JSON-LD, llms.txt) se corrigent en quelques heures. Les erreurs de contenu (profondeur, entités, FAQ) nécessitent 1 à 2 semaines de travail rédactionnel. L'autorité tierce (mentions externes) est un travail de fond qui s'échelonne sur 4 à 12 semaines selon votre secteur et votre réseau.
Ces erreurs affectent-elles toutes les IA de la même façon ?
Non. ChatGPT et Claude sont très sensibles à l'autorité tierce (Erreur 2). Perplexity est particulièrement sensible à la structure FAQ (Erreur 9) et aux robots autorisés (Erreur 1). Gemini pénalise fortement l'absence de JSON-LD (Erreur 5) car il croise les données structurées Google. Mistral valorise la densité d'entités (Erreur 3). C'est pourquoi mesurer sa visibilité sur les 6 moteurs simultanément est indispensable — une correction qui améliore votre score sur ChatGPT peut ne pas impacter Perplexity.
Une PME avec un petit site peut-elle vraiment apparaître dans les IA ?
Oui. La taille du site est moins importante que la cohérence sémantique et l'autorité tierce. Une PME avec 5 pages bien structurées, un llms.txt précis, un JSON-LD complet et 10 mentions sur des sites sectoriels reconnus peut surpasser un site de 200 pages mal optimisé pour les IA. Les LLMs sélectionnent par pertinence et fiabilité, pas par volume.
L'erreur la plus fréquente que vous observez chez les PME françaises ?
L'Erreur 1 (robots IA bloqués) est présente chez environ 40 % des PME que nous analysons, souvent sans que le dirigeant en soit conscient. C'est généralement une configuration héritée d'un prestataire web qui a appliqué une règle de « protection contre le scraping » sans distinguer les robots IA légitimes des scrapers malveillants. C'est la première chose à vérifier, car c'est une erreur binaire : bloqué = invisible, autorisé = potentiellement visible.
Comment savoir si une correction a eu un effet ?
Testez manuellement sur ChatGPT, Claude, Mistral, Perplexity, Meta AI et Gemini avec des requêtes sectorielles (« meilleur [votre métier] pour PME », « quelle solution [votre secteur] »). Notez vos résultats avant et 4 semaines après correction. Pour un suivi systématique, des outils comme Diria mesurent votre score de visibilité en temps réel sur les 6 moteurs et indiquent quelles erreurs restent à corriger.